RNN循环神经网络
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 HUII's Blog!
相关推荐
2022-02-17
C&C++ from 于仕琪 南科大
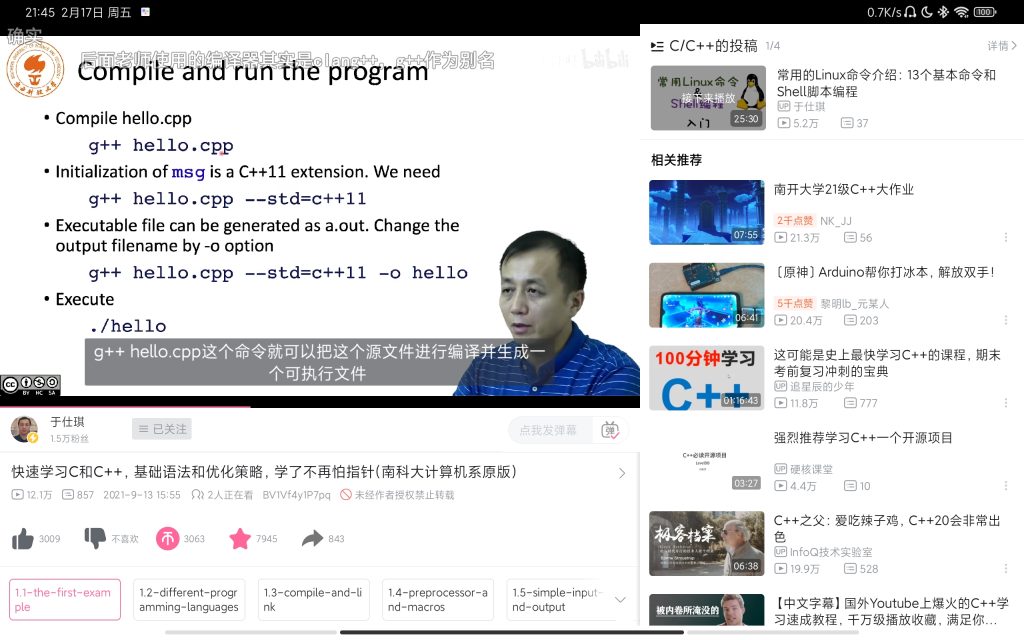
课程地址:快速学习C和C++,基础语法和优化策略,学了不再怕指针(南科大计算机系原版)_哔哩哔哩_bilibili github地址:ShiqiYu/CPP: Lecture notes, projects and other materials for Course ‘CS205 C/C++ Program Design’ at Southern University of Science and Technology. (github.com) 课程 由于之前已经学过C语言,部分内容将跳过。 Week1the first example1234567891011121314151617//C++ example in C++11#include <iostream>#include <vector>#include <string>using namespace std;int main(){ vector<string> msg {"Hello", "C++",...

2022-12-21
R-CNN——RCNN系列算法Ⅰ
前言由于基于深度学习的方法较传统方法相比,准确率有了较明显的提升,故只学习基于深度学习方法的目标检测。 RCNN系列算法将从论文着手,结合其他资料,学习R-CNN、 Fast R-CNN、Faster R-CNN。 R-CNN的全称是Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。[ref] R-CNN_百度百科 (baidu.com)[/ref] 论文与源码原论文:1311.2524.pdf (arxiv.org) 代码:rbgirshick/rcnn: R-CNN: Regions with Convolutional Neural Network Features (github.com) R-CNN论文 R-CNN下载 摘要 摘要 摘要首先开门见山地指出与之前传统方法相比,R-CNN一下子将平均精度提高了30%(至53.3%),可见其有效性。 指出了本文的两个要点:① 高容量卷积神经网络自底向上,以便定位和分割对象;② 当标记的训练数据稀少时,用于辅助...
2023-03-14
深度学习相关概念
持续更新 术语backbone翻译为骨干网络的意思,既然说是主干网络,就代表其是网络的一部分,这个主干网络大多时候指的是提取特征的网络,其作用就是提取图片中的信息,供后面的网络使用。 这些网络经常使用的是resnet、VGG等,而不是我们自己设计的网络,因为这些网络已经证明了在分类等问题上的特征提取能力是很强的。在用这些网络作为backbone的时候,都是直接加载官方已经训练好的模型参数,后面接着我们自己的网络。让网络的这两个部分同时进行训练,因为加载的backbone模型已经具有提取特征的能力了,在我们的训练过程中,会对他进行微调,使得其更适合于我们自己的任务。 主要分成三类:\CNNs结构, Transformer结构(如ViT及衍生算法,比如PVT),CNNs+Transformer结构**。深度学习常用的backbone有哪些深度学习backbone万里鹏程转瞬至的博客-CSDN博客 backbone 相关概念还有: Neck:是放在backbone和head之间的,是为了更好的利用backbone提取的特征。 Bottleneck:瓶颈的意思,通常指的是网网络输入的...
2022-12-20
图像目标检测基本概念与算法
目标检测任务概述机器视觉的中心任务是从图像中解析出可供计算机理解的信息。根据后续任务的需求,可将其分为四个主要层次:分类(Classification)、定位(Location)、检测(Detection)、分割(Segmentation)必读!计算机视觉四大基本任务(分类、定位、检测、分割) (qq.com)。 分类(图a)、定位、检测(图b)、语义分割(图c)、和实例分割(图d) 分类任务关心图像整体,给出整张图像的内容描述即可,而检测则关心特定物体目标,要求同时获得目标类别信息和位置信息。 图像检测 发展沿革 目标检测发展沿革 目标检测究竟发展到了什么程度?| 目标检测发展22年 - 知乎 (zhihu.com) 阶段一:传统目标检测方法传统检测算法流程可概括如下: 选取感兴趣区域,选取可能包含物体的区域 对可能包含物体的区域进行特征提取 对提取的特征进行检测分类 传统检测流程 较为知名的传统方法有:Viola Jones Detectors、HOG Detector、Deformable Part-based Model (DPM)[目标检测的传统方法概...
2022-12-23
Fast R-CNN——RCNN系列算法Ⅱ
前言Fast R-CNN在VOC-07数据集上将检测精度mAP从58.5%提高到70.0%,检测速度比R-CNN提高了200倍。 从论文页数来看,Fast R-CNN仅9页,与R-CNN的21页相比,也“精简”了不少。 论文与源码原论文:Fast R-CNN (thecvf.com) 代码:rbgirshick/fast-rcnn: Fast R-CNN (github.com) Fast R-CNN论文 Girshick_Fast_R-CNN_ICCV_2015_paper下载 摘要 摘要 从摘要可以看出,Fast R-CNN采用了几项创新技术来提升训练与测试的速度和精度,与R-CNN相比,Fast R-CNN采用更深的VGG16,但训练速度快了9倍,测试速度快了213倍,并且获得了更高的均值平均精度(Mean Average Precision)。 结论 结论 Fast R-CNN是在R-CNN 和 SPPnet基础上进行升级的,并且提出“稀疏目标的建议似乎可以提高探测器的质量”。 介绍 现况介绍 作者认为前期的相关工作存在缓慢和不优雅的问题,主要原因是需要对对...
2023-02-12
YOLO v1笔记
学习内容来源:同济子豪兄的个人空间_哔哩哔哩_bilibili 作者介绍Joseph Redmon,You Only Look Once、YOLO9000、YOLOv3。 2020年起不再从事计算机视觉研究。 作者宣布停止CV研究 预测阶段(前向判断) YOLOv1结构 输入一个4484483的图像,经过一系列的卷积和池化操作,得到一个771024的feature map,将其拉平,送入4096个神经元的FC层中,输出结果输入到1470(7730)个神经元的FC层中,输出1470维向量,reshape成7730的tensor。 why7*7*30?论文中将图像划分为SS个网格,这里S取7。每个grid cell(网格)可以预测出B个bounding box(预测框,包含x,y【中心坐标】,h,w【宽高】,c【置信度confidence,包含物体的概率,用框线粗细表示,粗的置信度高】),这里B取2。**30=2\5+20。2:2个框;5:5个参数;20:Pascal VOC中20个类别的条件概率**(该grid cell在包含物体情况下是xx的概率)。 输出7730模...
评论