Operating System: A body of software, in fact, that is responsible for making it easy to run programs (even allowing you to seemingly run many at the same time), allowing programs to share memory, enabling programs to interact with devices, and other fun stuff like that. (OSTEP)
Bill Gates 和 Paul Allen 在 1975 年实现了 Altair 8800 上的 BASIC 解释器
操作系统:能载入多个程序到内存且调度它们的管理程序。
为防止程序之间形成干扰,操作系统自然地将共享资源 (如设备) 以 API 形式管理起来
有了进程 (process) 的概念
进程在执行 I/O 时,可以将 CPU 让给另一个进程
在多个地址空间隔离的程序之间切换
虚拟存储使一个程序出 bug 不会 crash 整个系统
操作系统中自然地增加进程管理 API
既然可以在程序之间切换,为什么不让它们定时切换呢?
Multics (MIT, 1965):现代分时操作系统诞生
1970s+
硬件:集成电路空前发展,个人电脑兴起,“计算机” 已与今日无大异
CISC 指令集;中断、I/O、异常、MMU、网络
个人计算机 (PC 机)、超级计算机……
软件
PASCAL (1970), C (1972), …
今天能办到的,那个时代已经都能办到了——上天入地、图像声音视频、人工智能……
个人开发者 (Geek Network) 走上舞台
操作系统:分时系统走向成熟,UNIX 诞生并走向完善,奠定了现代操作系统的形态。
1973: 信号 API、管道 (对象)、grep (应用程序)
1983: BSD socket (对象)
1984: procfs (对象)……
UNIX 衍生出的大家族
1BSD (1977), GNU (1983), MacOS (1984), AIX (1986), Minix (1987), Windows (1985), Linux 0.01 (1991), Windows NT (1993), Debian (1996), Windows XP (2002), Ubuntu (2004), iOS (2007), Android (2008), Windows 10 (2015), ……
for line in fileinput.input(): # Load "A=0; B=1; ..." to current context exec(line)
# Render the seven-segment display pic = DISPLAY for seg in set(DISPLAY): if seg.isalpha(): val = globals()[seg] # 0 or 1 pic = pic.replace(seg, BLOCK[val])
// Wire and register specification wire X, Y, X1, Y1, A, B, C, D, E, F, G; reg b1 = {.in = &X1, .out = &X}; reg b0 = {.in = &Y1, .out = &Y};
// Dump wire values at the end of each cycle void end_cycle() { PRINT(A); PRINT(B); PRINT(C); PRINT(D); PRINT(E); PRINT(F); PRINT(G); }
int main() { CLOCK { // 1. Wire network specification (logic gates) X1 = AND(NOT(X), Y); Y1 = NOT(OR(X, Y)); A = D = E = NOT(Y); B = 1; C = NOT(X); F = Y1; G = X;
// 2. Lock data in flip-flops and propagate output to wires b0.value = *b0.in; b1.value = *b1.in; *b0.out = b0.value; *b1.out = b1.value; } }
Makefile
1 2 3 4 5 6 7 8
a.out: logisim.c gcc $(CFLAGS) logisim.c
run: a.out ./a.out | python3 seven-seg.py # The UNIX Philosophy
def step(self): """Proceed with the thread until its next trap.""" syscall, args, *_ = self._func.send(self.retval) self.retval = None return syscall, args
class Heap: pass # no member: self.__dict__ is the heap
@dataclass class Thread: context: Generator # program counter, local variables, etc. heap: Heap # a pointer to thread's "memory"
@dataclass class Storage: persist: dict # persisted storage state buf: dict # outstanding operations yet to be persisted
### 2.2 The OperatingSystem class
class OperatingSystem: """An executable operating system model.
The operating system model hosts a single Python application with a main() function accessible to a shared heap and 9 system calls (marked by the @syscall decorator). An example:
At any moment, this model keeps tracking a set of threads and a "currently running" one. Each thread consists of a reference to a heap object (may be shared with other threads) and a private context (program counters, local variables, etc.). A thread context is a Python generator object, i.e., a stack-less coroutine [1] that can save the running context and yield itself.
For applications, the keyword "yield" is reserved for system calls. For example, a "choose" system call [2]:
sys_choose(['A', 'B'])
is transpiled as yielding the string "sys_choose" followed by its parameters (choices):
res = yield 'sys_choose', ['A', 'B'].
Yield will transfer the control to the OS for system call handling and eventually returning a value ('A' or 'B') to the application.
Right after transferring control to the OS by "yield", the function state is "frozen", where program counters and local variables are accessible via the generator object. Therefore, OS can serialize its internal state--all thread's contexts, heaps, and virtual device states at this moment.
In this sense, operating system is a system-call driven state transition system:
(s0) --run first thread (main)-> (s1) --sys_choose and application execution-> (s2) --sys_sched and application execution-> (s3) ...
Real operating systems can be preemptive--context switching can happen non-deterministically at any program point, simply because processor can non-deterministically interrupt its currently running code and transfer the control to the operating system.
The OS internal implementation does NOT immediately process the system call: it returns all possible choices available at the moment and their corresponding processing logic as callbacks. For the example above, the "choose" system call returns a non-deterministic choice among given choices. The internal implementation thus returns
for later processing. Another example is non-deterministic context switching by yielding 'sys_sched'. Suppose there are threads t1 and t2 at the moment. The system call handler will return
in which switch_to(th) replaces the OS's current running thread with th (changes the global "heap" variable). Such deferred execution of system calls separates the mechanism of non-deterministic choices from the actual decision makers (e.g., an interpreter or a model checker). Once the decision is made, the simply call step(choice) and the OS will execute this choice by
choices[choice]()
with the application code (generator) being resumed.
This model provides "write" system call to immediately push data to a hypothetical character device like a tty associated with stdout. We model a block device (key-value store) that may lose data upon crash. The model assumes atomicity of each single block write (a key-value update). However, writes are merely to a volatile buffer which may non-deterministically lose data upon crash 3]. The "sync" system call persists buffered writes.
References:
[1] N. Schemenauer, T. Peters, and M. L. Hetland. PEP 255 - Simple generators. https://peps.python.org/pep-0255/ [2] J. Yang, C. Sar, and D. Engler. eXplode: a lightweight, general system for finding serious storage system errors. OSDI'06. [3] T. S. Pillai, V. Chidambaram, R. Alagappan, A. Al-Kiswany, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau. All file systems are not created equal: On the complexity of crafting crash consistent applications. OSDI'14. """
def __init__(self, init: Callable): """Create a new OS instance with pending-to-execute init thread.""" # Operating system states self._threads = [Thread(context=init(), heap=Heap())] self._current = 0 self._choices = {init.__name__: lambda: None} self._stdout = '' self._storage = Storage(persist={}, buf={})
@syscall def sys_spawn(self, func: Callable, *args): """Spawn a heap-sharing new thread executing func(args).""" def do_spawn(): self._threads.append( Thread( context=func(*args), # func() returns a new generator heap=self.current().heap, # shared heap ) ) return {'spawn': (lambda: do_spawn())}
@syscall def sys_fork(self): """Create a clone of the current thread with a copied heap.""" if all(not f.frame.f_locals['fork_child'] for f in inspect.stack() if f.function == '_step'): # this is parent; do fork # Deep-copying generators causes troubles--they are twined with # Python's runtime state. We use an (inefficient) hack here: replay # the entire trace and override the last fork() to avoid infinite # recursion. os_clone = OperatingSystem(self._init) os_clone.replay(self._trace[:-1]) os_clone._step(self._trace[-1], fork_child=True)
# Now os_clone._current is the forked process. Cloned thread just # yields a sys_fork and is pending for fork()'s return value. It # is necessary to mark cloned threads (in self._newfork) and send # child's fork() return value when they are scheduled for the # first time. def do_fork(): self._threads.append(os_clone.current()) self._newfork.add((pid := len(self._threads)) - 1) return 1000 + pid # returned pid starts from 1000
return {'fork': (lambda: do_fork())} else: return None # overridden fork; this value is never used because # os_clone is destroyed immediately after fork()
@syscall def sys_sched(self): """Return a non-deterministic context switch to a runnable thread.""" return { f't{i+1}': (lambda i=i: self._switch_to(i)) for i, th in enumerate(self._threads) if th.context.gi_frame is not None # thread still alive? }
### 2.3.2 Virtual character device (byte stream)
@syscall def sys_choose(self, choices): """Return a non-deterministic value from choices.""" return {f'choose {c}': (lambda c=c: c) for c in choices}
@syscall def sys_write(self, *args): """Write strings (space separated) to stdout.""" def do_write(): self._stdout += ' '.join(str(arg) for arg in args) return {'write': (lambda: do_write())}
### 2.3.3 Virtual block storage device
@syscall def sys_bread(self, key): """Return the specific key's associated value in block device.""" storage = self._storage return {'bread': (lambda: storage.buf.get(key, # always try to read from buffer first storage.persist.get(key, None) # and then persistent storage ) )}
@syscall def sys_sync(self): """Persist all buffered writes.""" def do_sync(): store = self._storage self._storage = Storage( persist=store.persist | store.buf, # write back buf={} ) return {'sync': (lambda: do_sync())}
@syscall def sys_crash(self): """Simulate a system crash that non-deterministically persists outstanding writes in the buffer. """ persist = self._storage.persist btrace = self._storage.buf.items() # block trace
crash_sites = ( lambda subset=subset: setattr(self, '_storage', Storage( # persist only writes in the subset persist=persist | dict(compress(btrace, subset)), buf={} ) ) for subset in # Mosaic allows persisting any subset of product( # pending blocks in the buffer *([(0, 1)] * len(btrace)) ) ) return dict(enumerate(crash_sites))
### 2.4 Operating system as a state machine
def replay(self, trace: list) -> dict: """Replay an execution trace and return the resulting state.""" for choice in trace: self._step(choice) return self.state_dump()
def _step(self, choice, fork_child=False): self._switch_to(self._current) self._trace.append(choice) # keep all choices for replay-based fork() action = self._choices[choice] # return value of sys_xxx: a lambda res = action()
try: # Execute current thread for one step func, args = self.current().context.send(res) assert func in SYSCALLS self._choices = getattr(self, func)(*args) except StopIteration: # ... and thread terminates self._choices = self.sys_sched()
# At this point, the operating system's state is # (self._threads, self._current, self._stdout, self._storage) # and outgoing transitions are saved in self._choices.
### 2.5 Misc and helper functions
def state_dump(self) -> dict: """Create a serializable Mosaic state dump with hash code.""" heaps = {} for th in self._threads: if (i := id(th.heap)) not in heaps: # unique heaps heaps[i] = len(heaps) + 1
os_state = { 'current': self._current, 'choices': sorted(list(self._choices.keys())), 'contexts': [ { 'heap': heaps[id(th.heap)], # the unique heap id 'pc': th.context.gi_frame.f_lineno, 'locals': th.context.gi_frame.f_locals, } if th.context.gi_frame is not None else None for th in self._threads ], 'heaps': { heaps[id(th.heap)]: th.heap.__dict__ for th in self._threads }, 'stdout': self._stdout, 'store_persist': self._storage.persist, 'store_buffer': self._storage.buf, }
h = hash(json.dumps(os_state, sort_keys=True)) + 2**63 return (copy.deepcopy(os_state) # freeze the runtime state | dict(hashcode=f'{h:016x}'))
def current(self) -> Thread: """Return the current running thread object.""" return self._threads[self._current]
def _switch_to(self, tid: int): self._current = tid globals()['os'] = self globals()['heap'] = self.current().heap if tid in self._newfork: self._newfork.remove(tid) # tricky: forked process must receive 0 return 0 # to indicate a child
## 3. The Mosaic runtime
class Mosaic: """The operating system interpreter and model checker.
The operating system model is a state transition system: os.replay() maps any trace to a state (with its outgoing transitions). Based on this model, two state space explorers are implemented:
- run: Choose outgoing transitions uniformly at random, yielding a single execution trace. - check: Exhaustively explore all reachable states by a breadth- first search. Duplicated states are not visited twice.
Both explorers produce the visited portion of the state space as a serializable object containing:
- source: The application source code - vertices: A list of operating system state dumps. The first vertex in the list is the initial state. Each vertex has a unique "hashcode" id. - edges: A list of 3-tuples: (source, target, label) denoting an explored source --[label]-> target edge. Both source and target are state hashcode ids. """
### 3.1 Model interpreter and checker
def run(self) -> dict: """Interpret the model with non-deterministic choices.""" os = OperatingSystem(self.entry) V, E = [os.state_dump() | dict(depth=0)], []
while (choices := V[-1]['choices']): choice = random.choice(choices) # uniformly at random V.append(os.replay([choice]) | dict(depth=len(V))) E.append((V[-2]['hashcode'], V[-1]['hashcode'], choice))
return dict(source=self.src, vertices=V, edges=E)
def check(self) -> dict: """Exhaustively explore the state space.""" class State: entry = self.entry
def extend(self, c): st = State(self.trace + (c,)) st.state = st.state | dict(depth=self.state['depth'] + 1) return st
st0 = State(tuple()) # initial state of empty trace queued, V, E = [st0], {st0.hashcode: st0.state}, []
while queued: st = queued.pop(0) for choice in st.state['choices']: st1 = st.extend(choice) if st1.hashcode not in V: # found an unexplored state V[st1.hashcode] = st1.state queued.append(st1) E.append((st.hashcode, st1.hashcode, choice))
self.src = src self.entry = context['main'] # must have a main()
## 4. Utilities
if __name__ == '__main__': parser = argparse.ArgumentParser( description='The modeled operating system and state explorer.' ) parser.add_argument( 'source', help='application code (.py) to be checked; must have a main()' ) parser.add_argument('-r', '--run', action='store_true') parser.add_argument('-c', '--check', action='store_true') args = parser.parse_args()
src = Path(args.source).read_text() mosaic = Mosaic(src) if args.check: explored = mosaic.check() else: explored = mosaic.run() # run is the default option
# Serialize the explored states and write to stdout. This encourages piping # the results to another tool following the UNIX philosophy. Examples: # # mosaic --run foo.py | grep stdout | tail -n 1 # quick and dirty check # mosaic --check bar.py | fx # or any other interactive visualizer # print(json.dumps(explored, ensure_ascii=False, indent=2))
void critical_section() { long cnt = atomic_fetch_add(&count, 1); int i = atomic_fetch_add(&nested, 1) + 1; if (i != 1) { printf("%d threads in the critical section @ count=%ld\n", i, cnt); assert(0); } atomic_fetch_add(&nested, -1); }
int volatile x = 0, y = 0, turn;
void TA() { while (1) { x = 1; BARRIER; turn = B; BARRIER; // <- this is critcal for x86 while (1) { if (!y) break; BARRIER; if (turn != B) break; BARRIER; } critical_section(); x = 0; BARRIER; } }
void TB() { while (1) { y = 1; BARRIER; turn = A; BARRIER; while (1) { if (!x) break; BARRIER; if (turn != A) break; BARRIER; } critical_section(); y = 0; BARRIER; } }
int xchg(int volatile *ptr, int newval) { int result; asm volatile( "lock xchgl %0, %1" : "+m"(*ptr), "=a"(result) : "1"(newval) : "memory" ); return result; }
int locked = 0;
void lock() { while (xchg(&locked, 1)) ; }
void unlock() { xchg(&locked, 0); }
void Tsum() { long nround = N / M; for (int i = 0; i < nround; i++) { lock(); for (int j = 0; j < M; j++) { sum++; // Non-atomic; can optimize } unlock(); } }
int main() { assert(N % M == 0); create(Tsum); create(Tsum); join(); printf("sum = %ld\n", sum); }
结果sum = 200000000
更强大的原子指令
更强大的原子指令
Compare and exchange (“test and set”)
Compare and exchange (“test and set”)
(lock) cmpxchg SRC, DEST
1 2 3 4 5 6 7
TEMP = DEST if accumulator == TEMP: ZF = 1 DEST = SRC else: ZF = 0 accumulator = TEMP
void Tproduce() { while (1) { retry: mutex_lock(&lk); if (!CAN_PRODUCE) { mutex_unlock(&lk); goto retry; } count++; printf("("); // Push an element into buffer mutex_unlock(&lk); } }
void Tconsume() { while (1) { retry: mutex_lock(&lk); if (!CAN_CONSUME) { mutex_unlock(&lk); goto retry; } count--; printf(")"); // Pop an element from buffer mutex_unlock(&lk); } }
int main(int argc, char *argv[]) { assert(argc == 2); n = atoi(argv[1]); setbuf(stdout, NULL); for (int i = 0; i < 8; i++) { create(Tproduce); create(Tconsume); } }
struct rule { int from, ch, to; } rules[] = { { A, '<', B }, { B, '>', C }, { C, '<', D }, { A, '>', E }, { E, '<', F }, { F, '>', D }, { D, '_', A }, }; int current = A, quota = 1;
 操作系统课程
操作系统课程 什么是操作系统
什么是操作系统 Fortran卡片
Fortran卡片 模拟数字系统运行结果
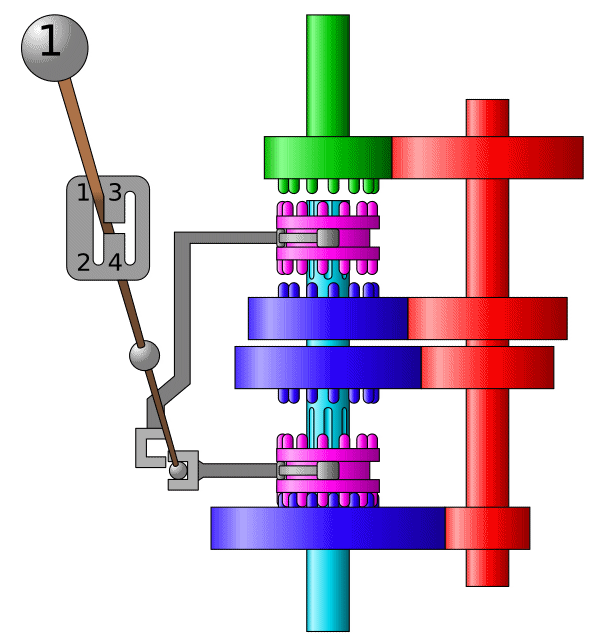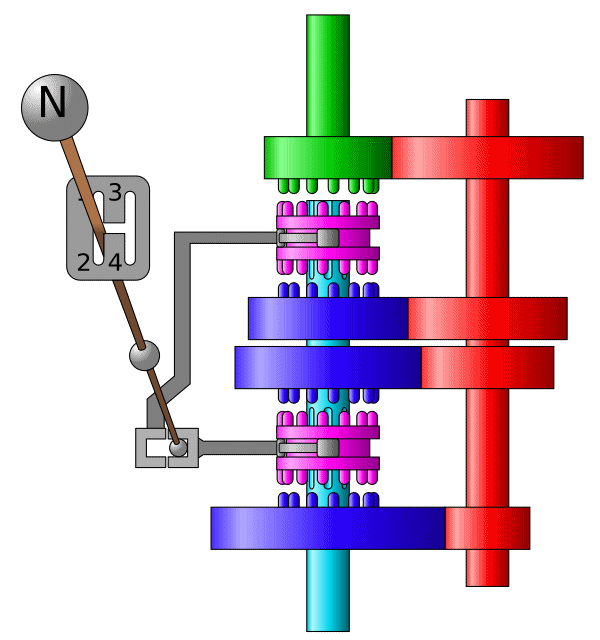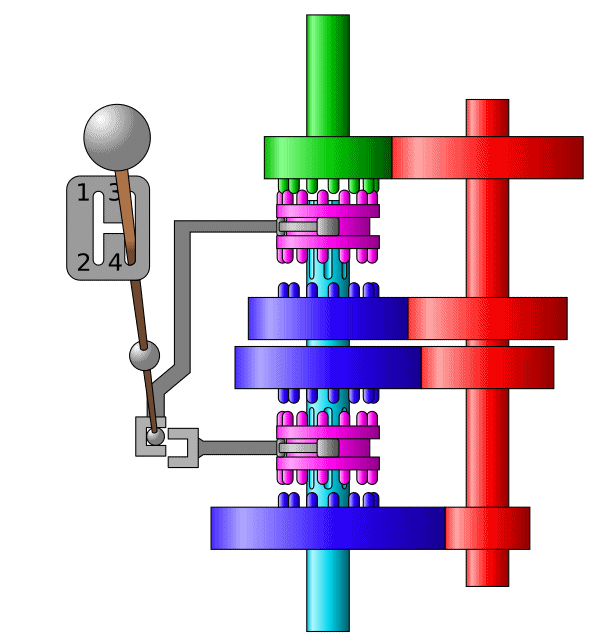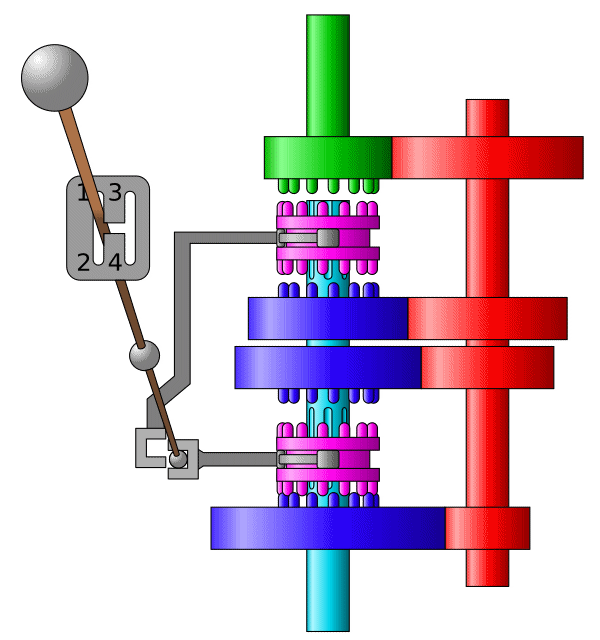
模拟数字系统运行结果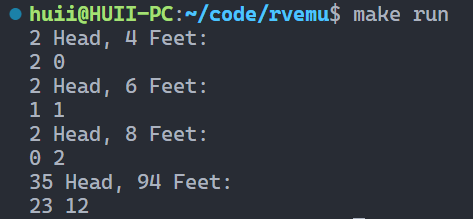 模拟 RISC-V 指令执行
模拟 RISC-V 指令执行 gcc运行日志
gcc运行日志 预编译结果(部分)
预编译结果(部分)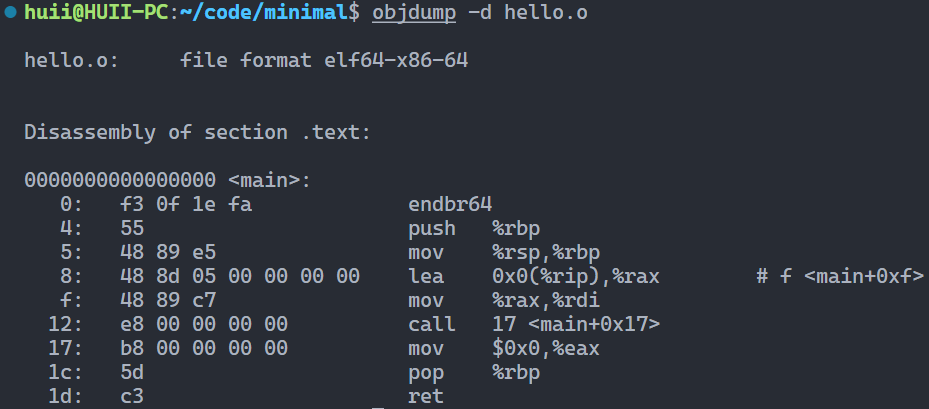 查看内容
查看内容 强行链接结果
强行链接结果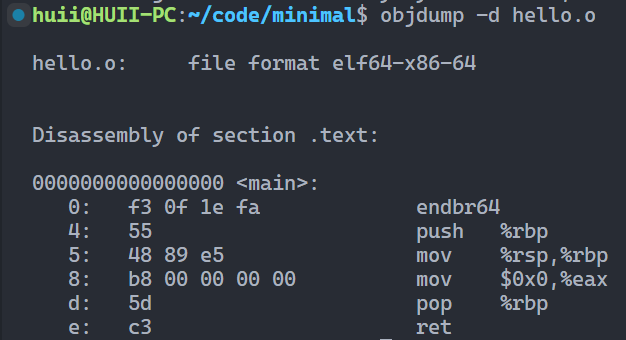 查看内容
查看内容 链接警告
链接警告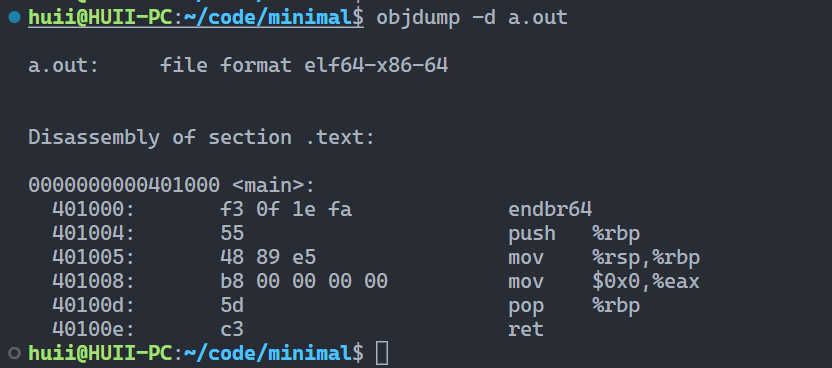 最小a.out
最小a.out 运行提示Segmentation fault
运行提示Segmentation fault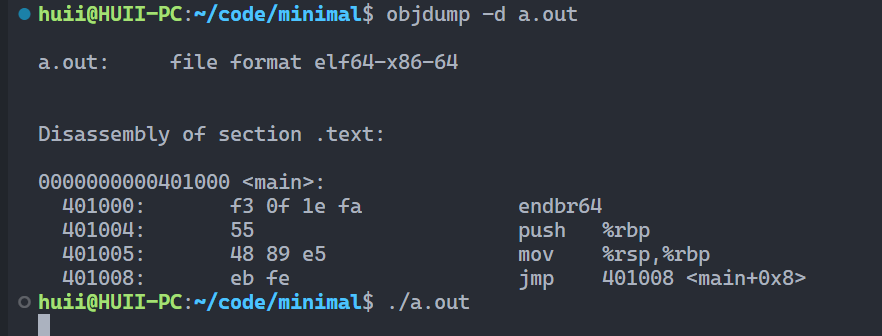 改为死循环
改为死循环 启动gdb
启动gdb text ui
text ui 寄存器状态
寄存器状态 返回时的出错
返回时的出错 运行结果
运行结果 查看行数
查看行数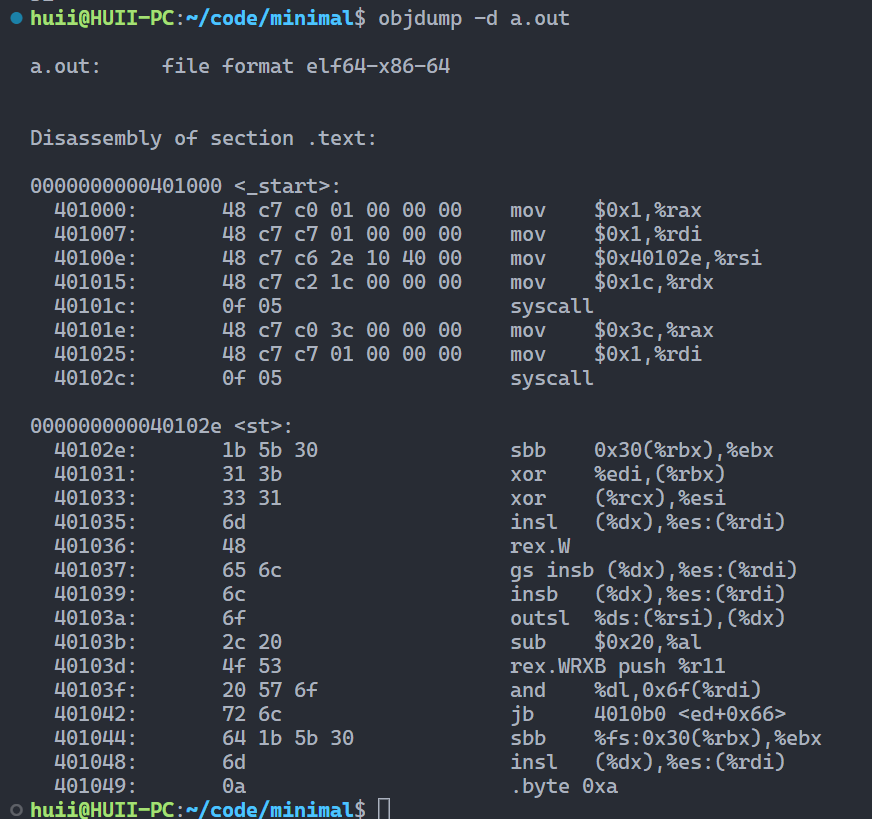 调试查看内容
调试查看内容 chatGPT理解的程序实现原理
chatGPT理解的程序实现原理 使用文本编辑器查看a.out
使用文本编辑器查看a.out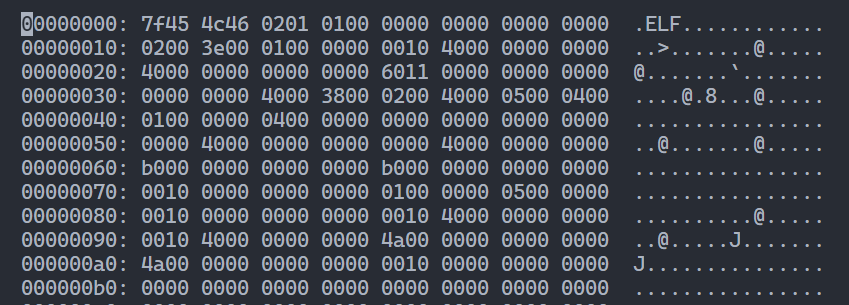 处理后
处理后 strace
strace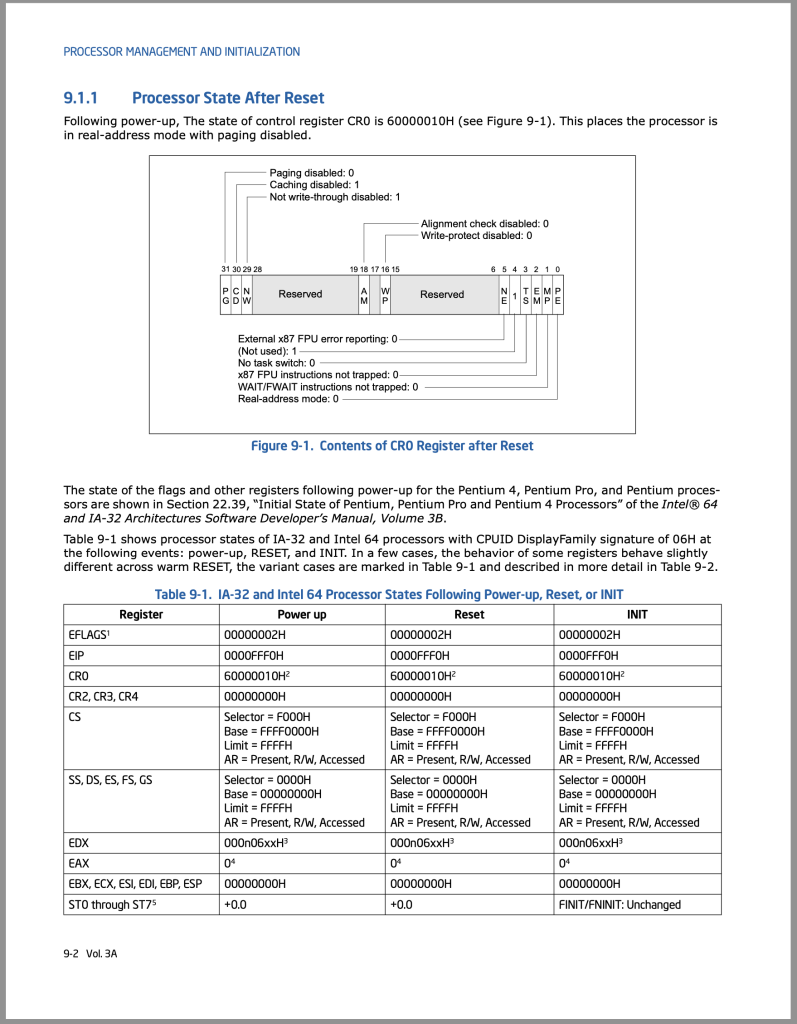 intel-cpu-reset
intel-cpu-reset bios-firmware
bios-firmware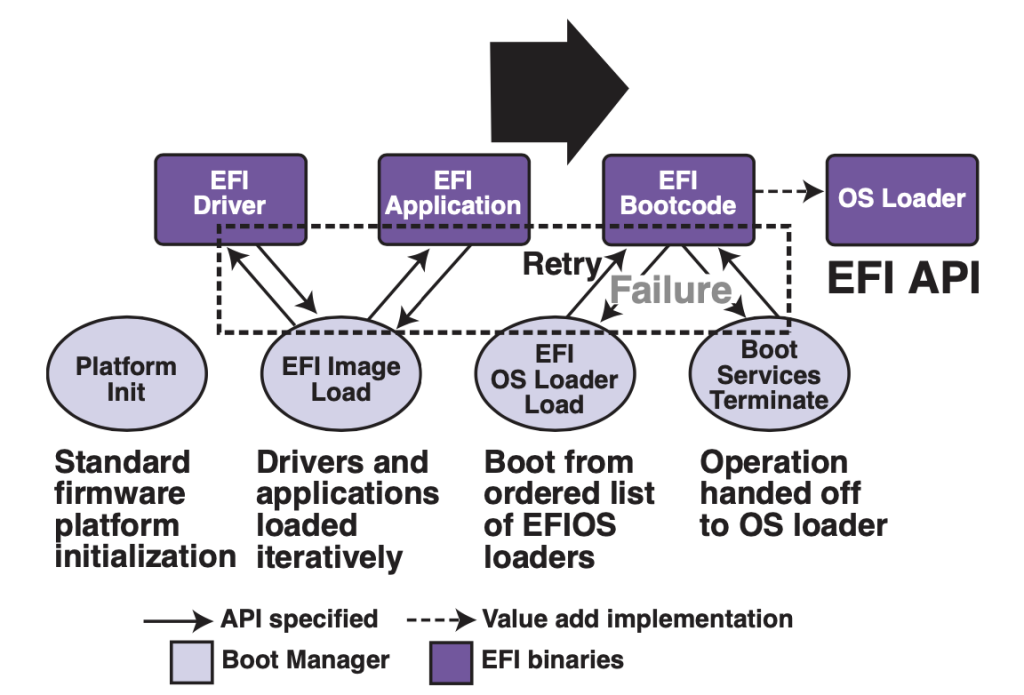 UEFI-booting-seq
UEFI-booting-seq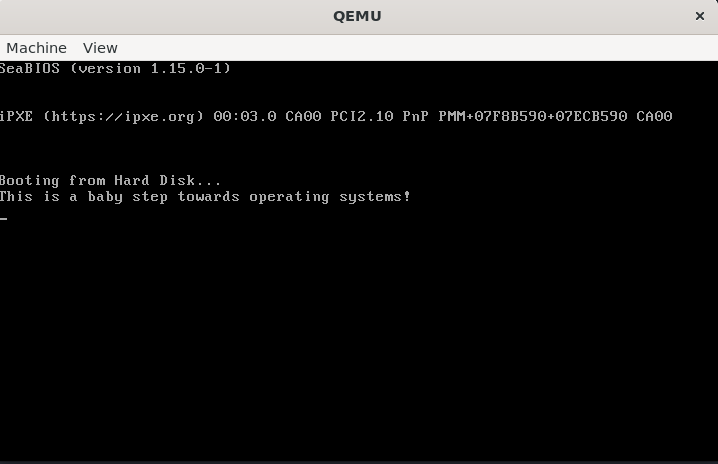 运行
运行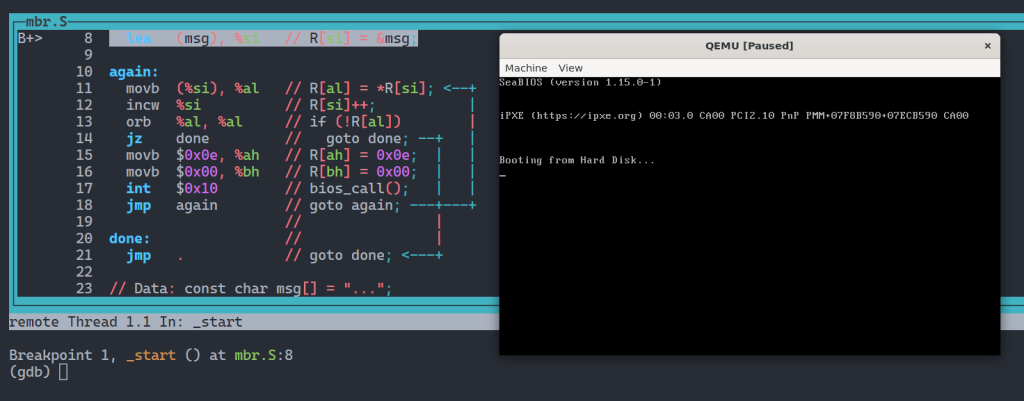 debug
debug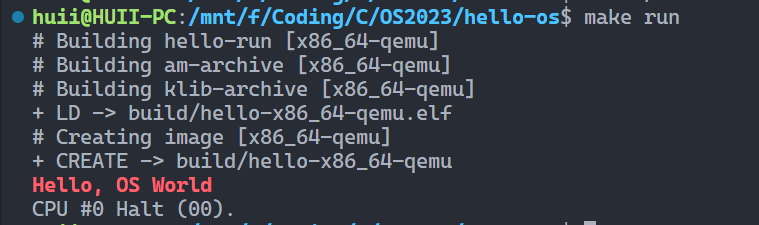 运行结果
运行结果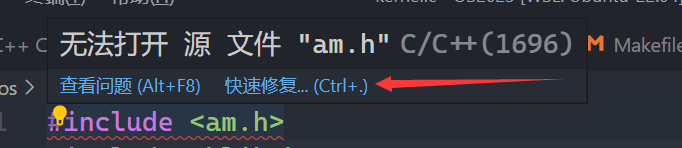 快速修复
快速修复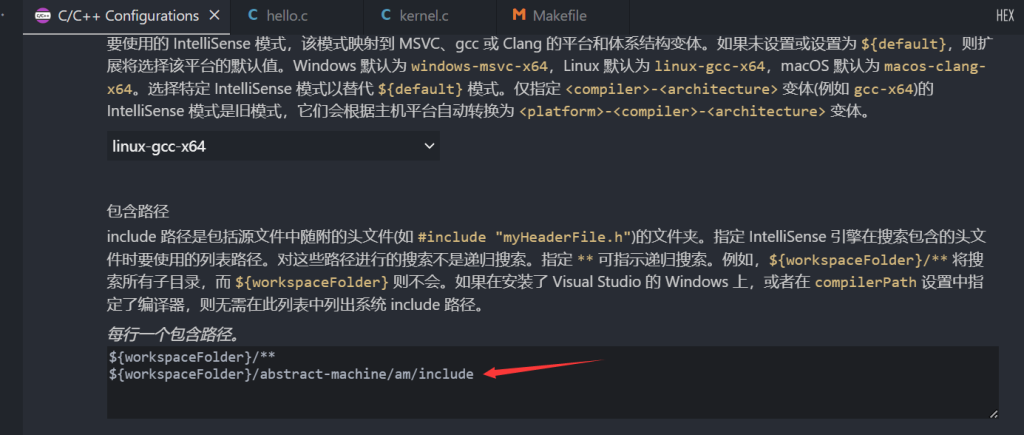 自动添加
自动添加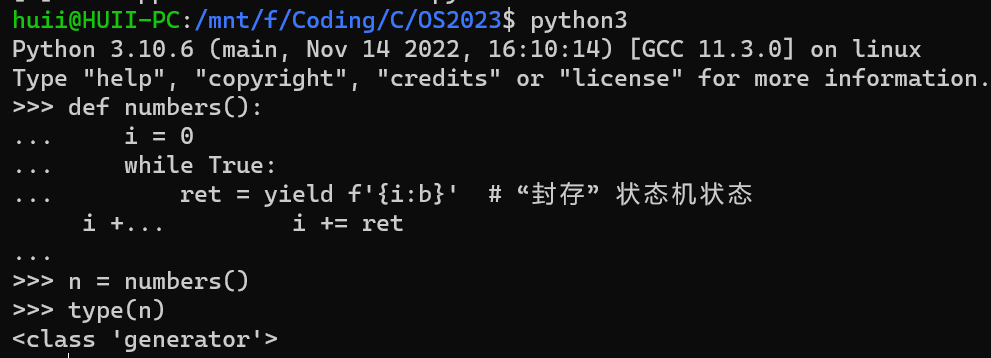 generator
generator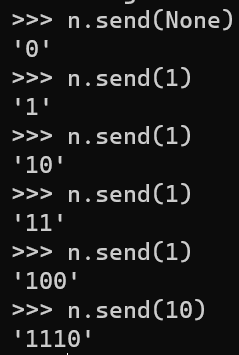 send,以二进制结果输出
send,以二进制结果输出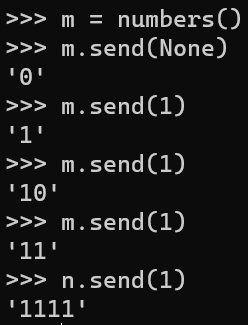 另外开一个线程m,切换
另外开一个线程m,切换 调用结果
调用结果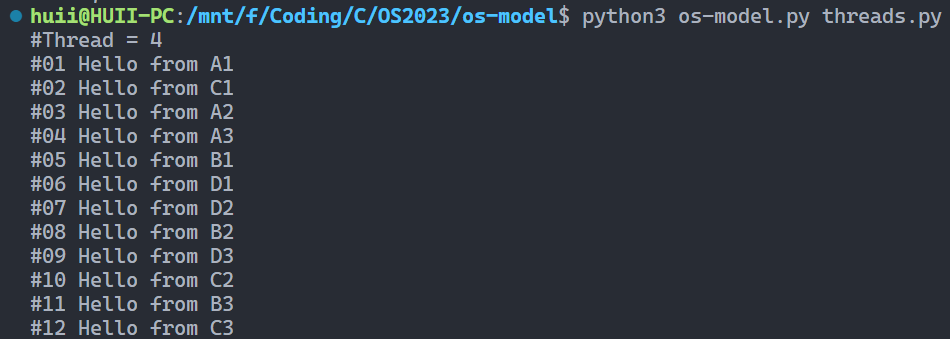 threads
threads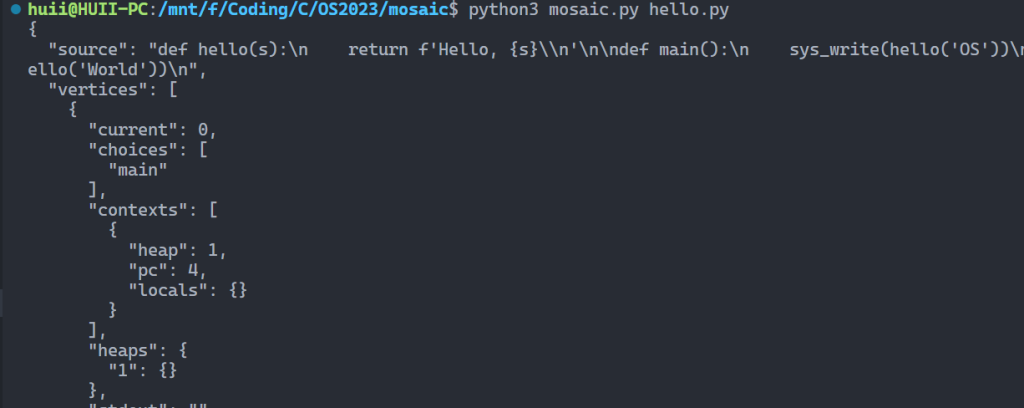 运行结果
运行结果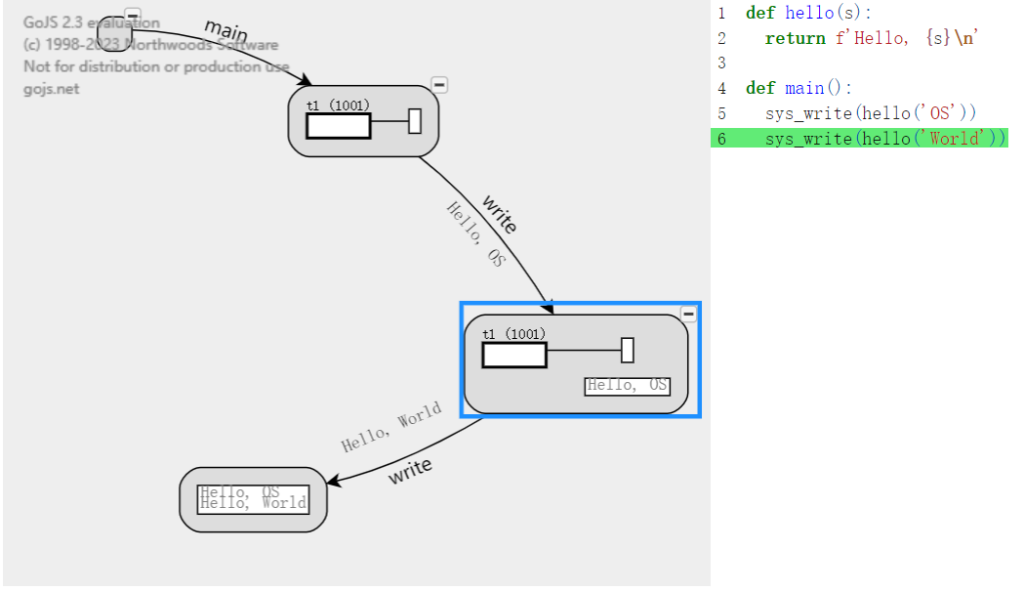 可视化结果
可视化结果 多线程程序最小值
多线程程序最小值 运行结果
运行结果 运行结果
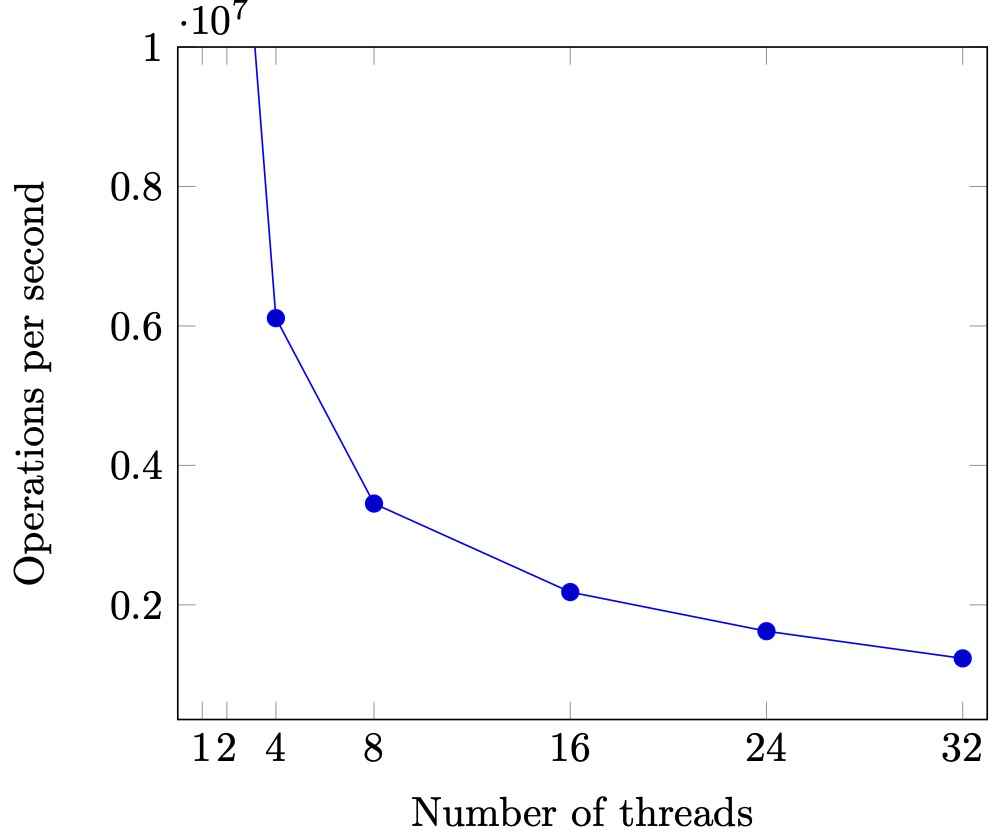
运行结果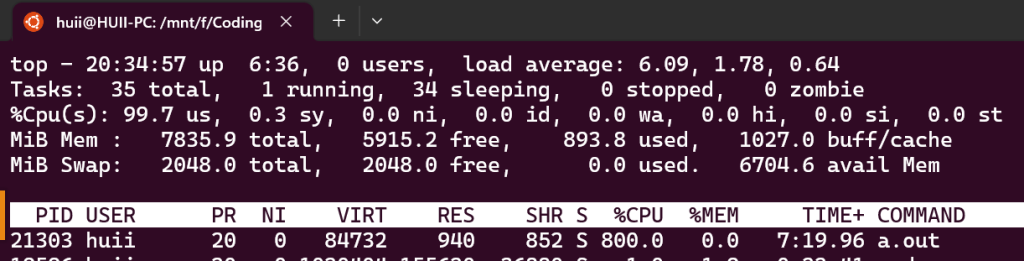 800%
800% 结果
结果 排序后结果
排序后结果 运行结果
运行结果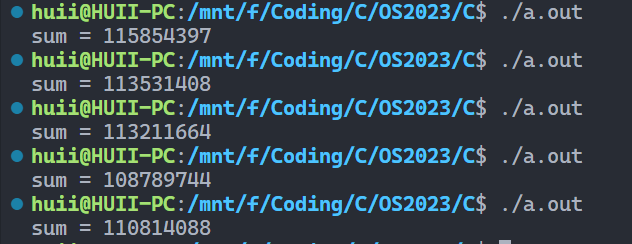 结果
结果 结果
结果
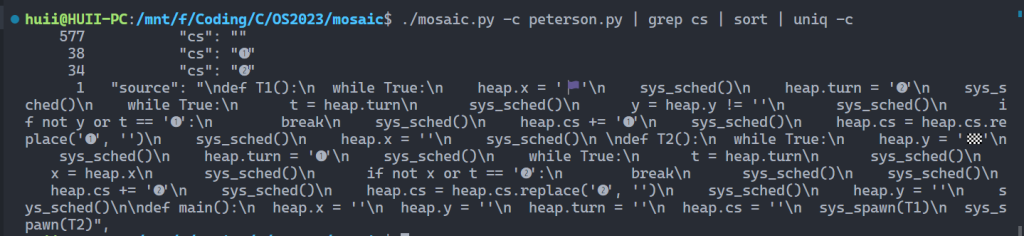 验证了正确性
验证了正确性 出错
出错
 正确结果,但是很慢
正确结果,但是很慢