第一章:多模态大语言模型概述
MLLM定义与核心价值
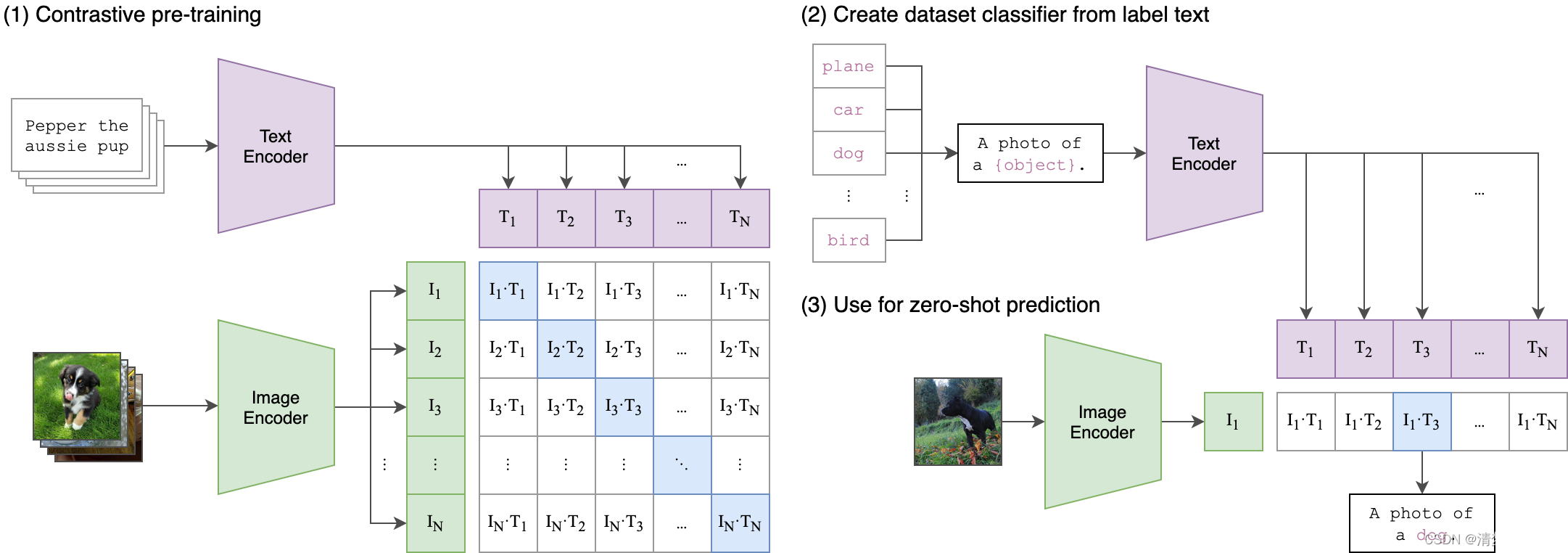
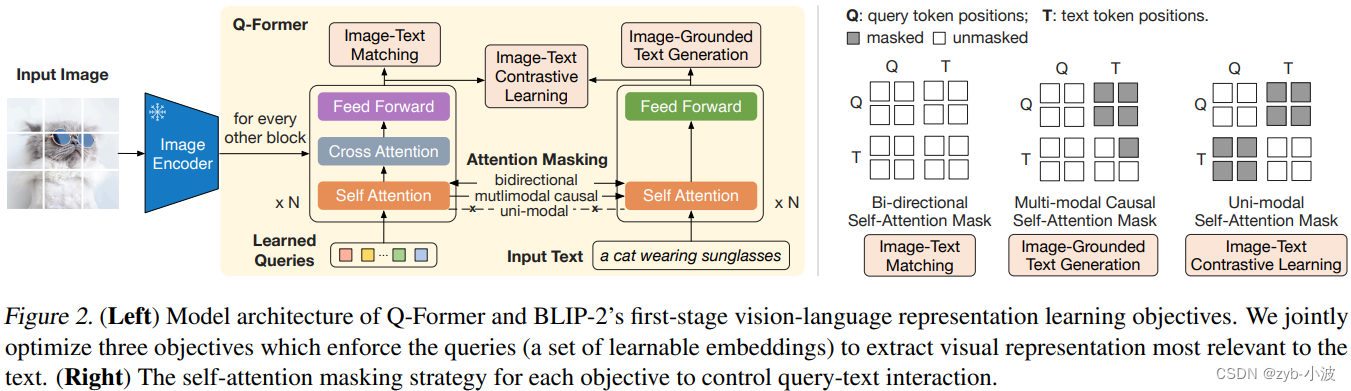
多模态大语言模型(Multimodal Large Language Model, MLLM)是指能够同时处理和理解多种模态信息(如文本、图像、音频等)的深度学习模型。
- 突破单一模态限制,实现跨模态理解与生成
- 具备强大的零样本和少样本学习能力
- 在视觉问答、图像描述、文档理解等任务中表现出色
- 推动AI从感知智能向认知智能迈进
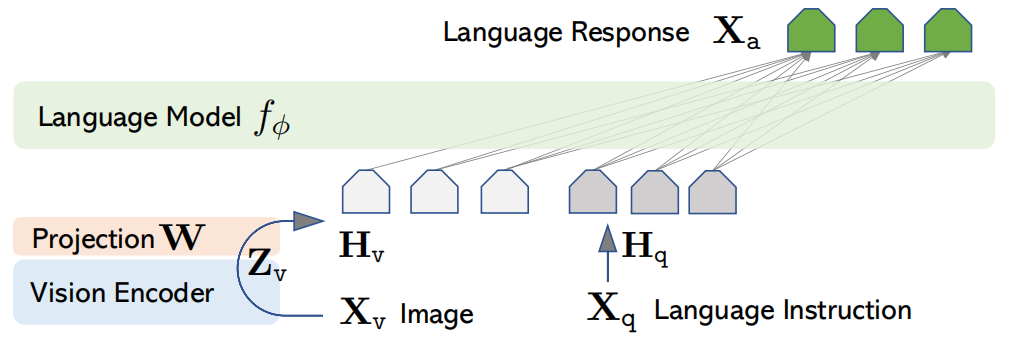
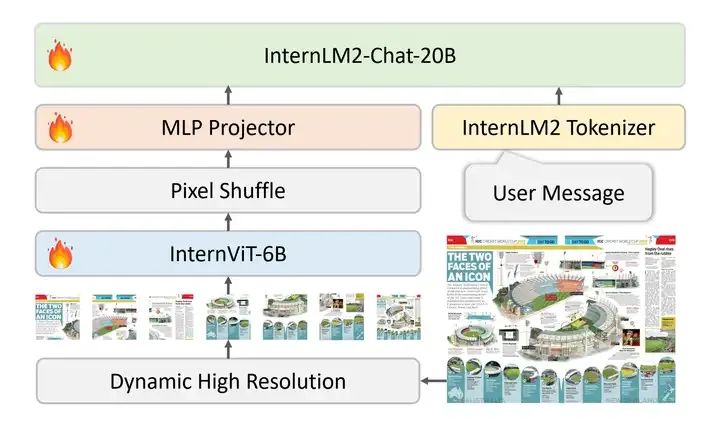
图:LLaVA总体架构设计
三要素架构图解
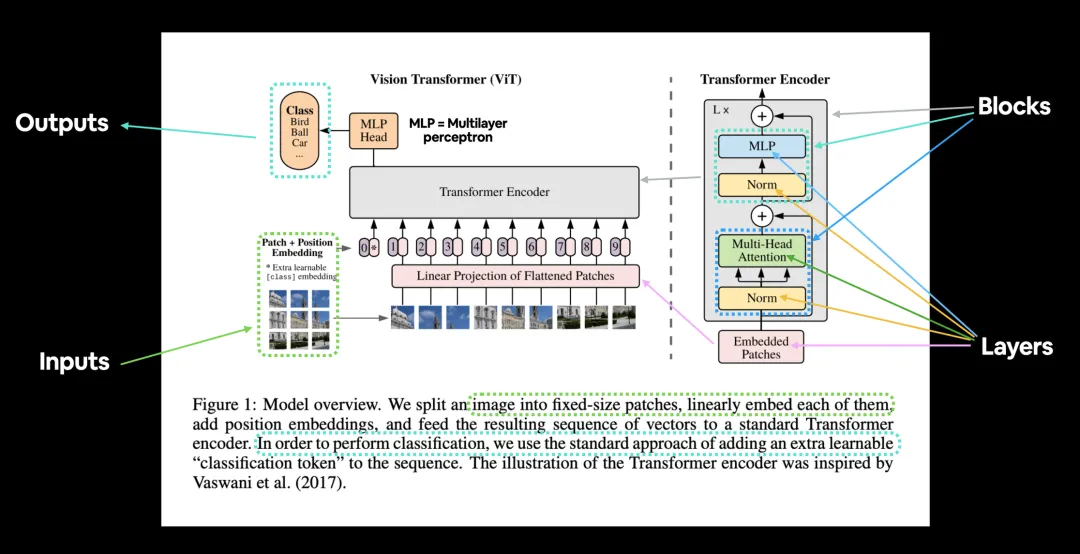
视觉编码器
处理图像输入,提取视觉特征
模态适配器
桥接视觉与语言表示空间
大语言模型
基于Transformer的语言理解
与传统CV模型的区别
传统CV模型
- • 单模态处理(纯图像)
- • 固定任务导向(分类、检测)
- • 缺乏语言交互能力
- • 预定义输出格式
MLLM模型
- • 多模态融合处理
- • 开放域任务适应
- • 自然语言交互
- • 灵活输出生成